Demos
Click thumbnails below to view different scenes.
a man run on the road





OmniWorld: A Multi-Domain and Multi-Modal Dataset for 4D World Modeling
Click thumbnails below to view different scenes.
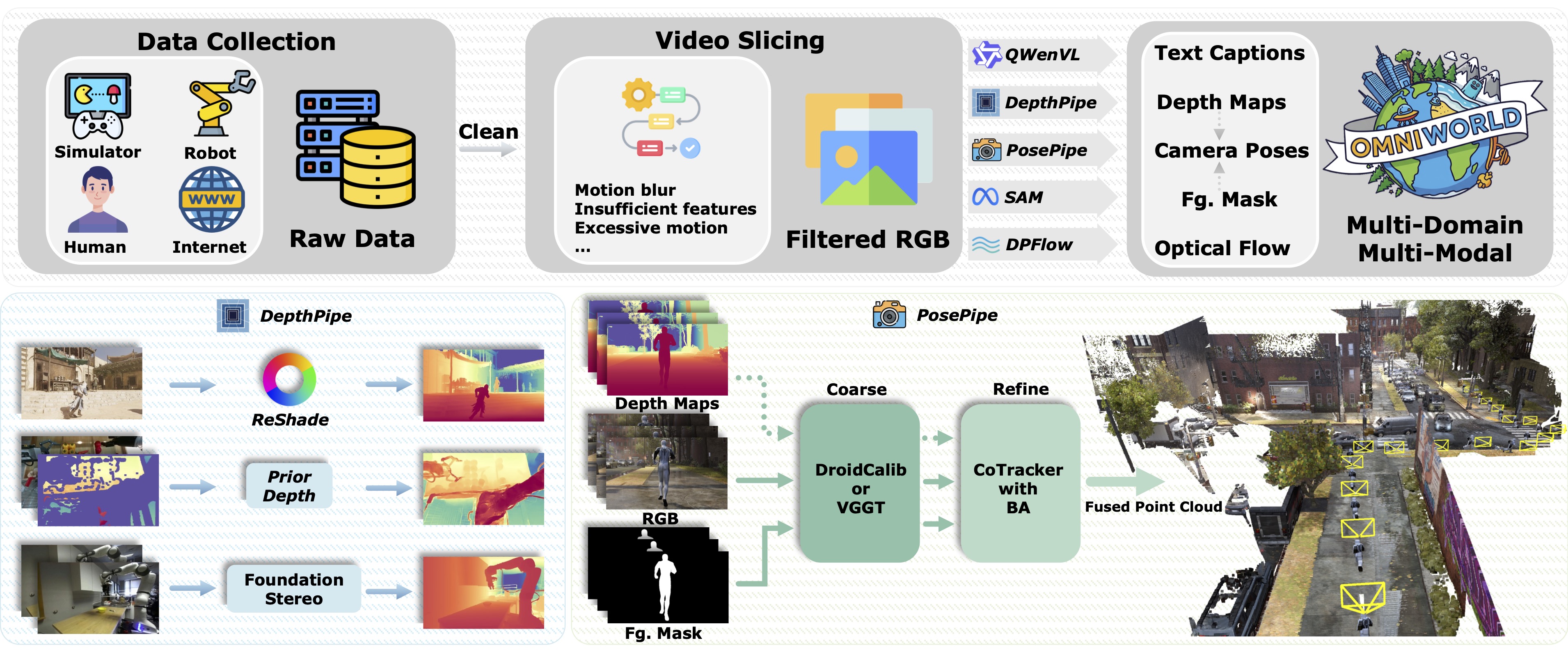
OmniWorld acquisition and annotation pipeline. We collect raw data from diverse domains and apply a video slicing filter to obtain high-quality RGB sequences. These sequences are then processed through a suite of specialized pipelines to generate multi-modal annotations, including text captions, depth maps, camera poses, foreground masks, and optical flow.
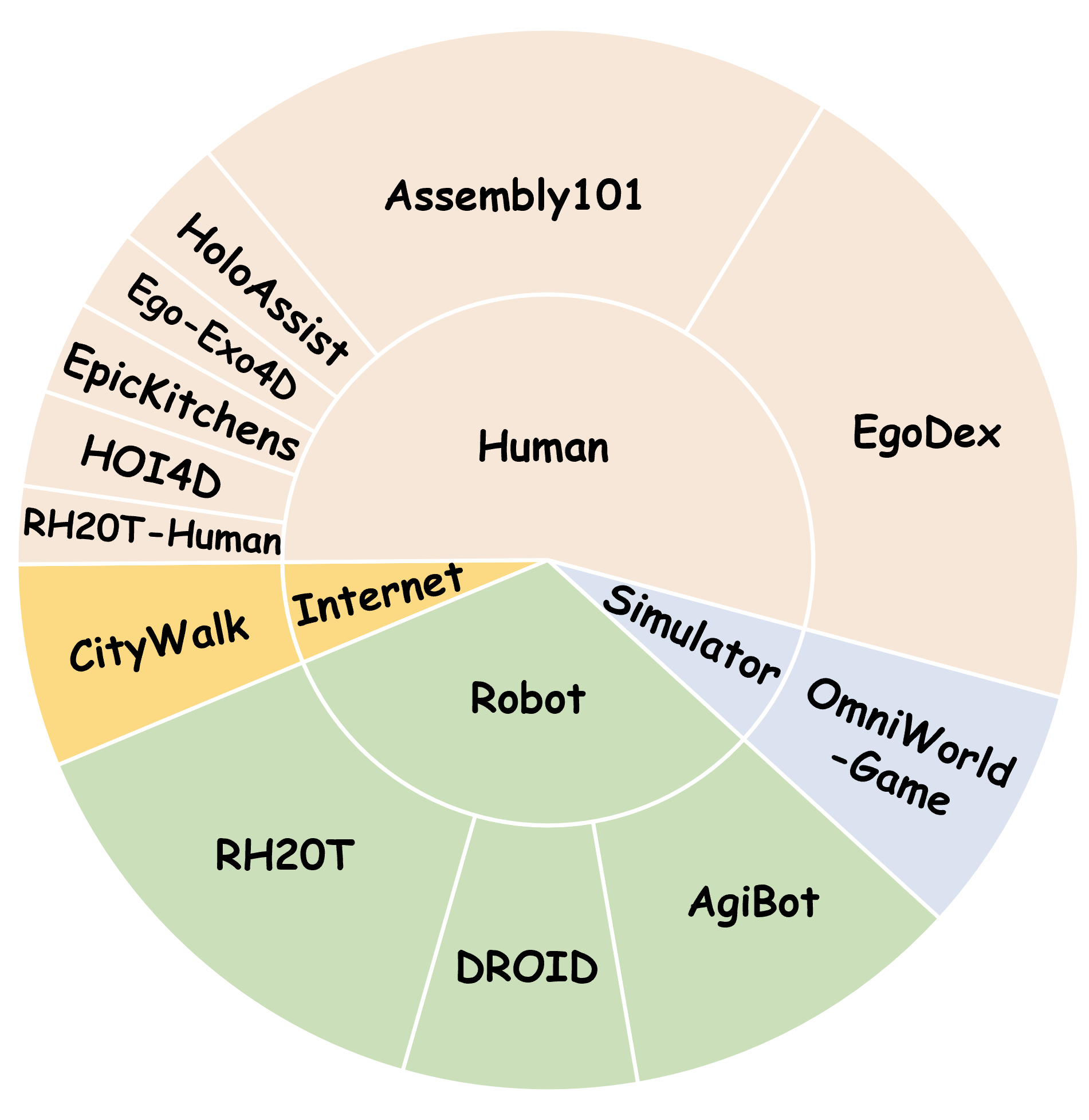
| Dataset | Domain | # Seq. | FPS | Resolution | # Frames | Depth | Camera | Text | Optical flow | Fg. masks |
|---|---|---|---|---|---|---|---|---|---|---|
| OmniWorld-Game | Simulator | 96K | 24 | 1280×720 | 18,515K | 🙂 | 🙂 | 🙂 | 🙂 | 🙂 |
| AgiBot | Robot | 20K | 30 | 640×480 | 39,247K | 🙂 | ✓ | ✓ | ✗ | 🙂 |
| DROID | Robot | 35K | 60 | 1280×720 | 26,643K | 🙂 | ✓ | 🙂 | 🙂 | 🙂 |
| RH20T | Robot | 109K | 10 | 640×360 | 53,453K | ✗ | ✓ | 🙂 | 🙂 | 🙂 |
| RH20T-Human | Human | 73K | 10 | 640×360 | 8,875K | ✗ | ✓ | 🙂 | ✗ | ✗ |
| HOI4D | Human | 2K | 15 | 1920×1080 | 891K | 🙂 | 🙂 | 🙂 | 🙂 | ✓ |
| Epic-Kitchens | Human | 15K | 30 | 1280×720 | 3,635K | ✗ | 🙂 | 🙂 | ✗ | ✗ |
| Ego-Exo4D | Human | 4K | 30 | 1024×1024 | 9,190K | ✗ | ✓ | 🙂 | 🙂 | ✗ |
| HoloAssist | Human | 1K | 30 | 896×504 | 13,037K | ✗ | 🙂 | 🙂 | 🙂 | ✗ |
| Assembly101 | Human | 4K | 60 | 1920×1080 | 110,831K | ✗ | ✓ | 🙂 | 🙂 | 🙂 |
| EgoDex | Human | 242K | 30 | 1280×720 | 76,631K | ✗ | ✓ | 🙂 | ✗ | ✗ |
| CityWalk | Internet | 7K | 30 | 1280×720 | 13,096K | ✗ | 🙂 | ✓ | ✗ | ✗ |
OmniWorld structure. 🙂 indicates the modality is newly (re-)annotated by us, ✓ denotes ground-truth data that already exists in the original dataset, and ✗ marks missing modalities.
| Dataset | Scene Type | Motion | Resolution | # Frames | Depth | Camera | Text | Optical flow | Fg. masks |
|---|---|---|---|---|---|---|---|---|---|
| MPI Sintel | Mixed | Dynamic | 1024×436 | 1K | ✓ | ✓ | ✗ | ✓ | ✓ |
| FlyingThings++ | Outdoor | Dynamic | 960×540 | 28K | ✓ | ✗ | ✗ | ✓ | ✓ |
| TartanAir | Mixed | Dynamic | 640×480 | 1,000K | ✓ | ✓ | ✗ | ✓ | ✓ |
| BlendedMVS | Mixed | Static | 768×576 | 17K | ✓ | ✓ | ✗ | ✗ | ✗ |
| HyperSim | Indoor | Static | 1024×768 | 77K | ✓ | ✓ | ✗ | ✗ | ✓ |
| Dynamic Replica | Indoor | Dynamic | 1280×720 | 169K | ✓ | ✓ | ✗ | ✓ | ✓ |
| Spring | Mixed | Dynamic | 1920×1080 | 23K | ✓ | ✓ | ✗ | ✓ | ✗ |
| EDEN | Outdoor | Static | 640×480 | 300K | ✓ | ✓ | ✗ | ✓ | ✓ |
| PointOdyssey | Mixed | Dynamic | 960×540 | 216K | ✓ | ✓ | ✗ | ✗ | ✓ |
| SeKai-Game | Outdoor | Dynamic | 1920×1080 | 4,320K | ✗ | ✓ | ✓ | ✗ | ✗ |
| OmniWorld-Game (Ours) | Mixed | Dynamic | 1280×720 | 18,515K | ✓ | ✓ | ✓ | ✓ | ✓ |
Comparisons between OmniWorld-Game and existing synthetic datasets. OmniWorld-Game surpasses existing public synthetic datasets in modal diversity and data scale. ✓ denotes available modalities; ✗ denotes missing ones.

@article{zhou2025omniworld,
title={OmniWorld: A Multi-Domain and Multi-Modal Dataset for 4D World Modeling},
author={Yang Zhou and Yifan Wang and Jianjun Zhou and Wenzheng Chang and Haoyu Guo and Zizun Li and Kaijing Ma and Xinyue Li and Yating Wang and Haoyi Zhu and Mingyu Liu and Dingning Liu and Jiange Yang and Zhoujie Fu and Junyi Chen and Chunhua Shen and Jiangmiao Pang and Kaipeng Zhang and Tong He},
journal={arXiv preprint arXiv:2509.12201},
year={2025}
}